Setting up connection profiles
In case of minimal downtime migration, Spanner Migration Tool needs information about connection profiles which are required by the datastream. There are two connection profiles that need to be set up - source connection profile and target connection profile.
Table of contents
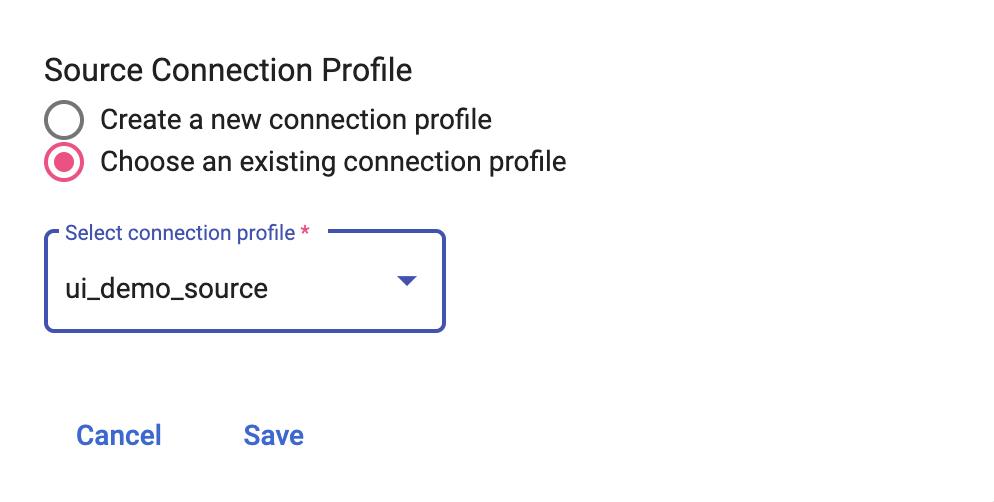
Source connection profile
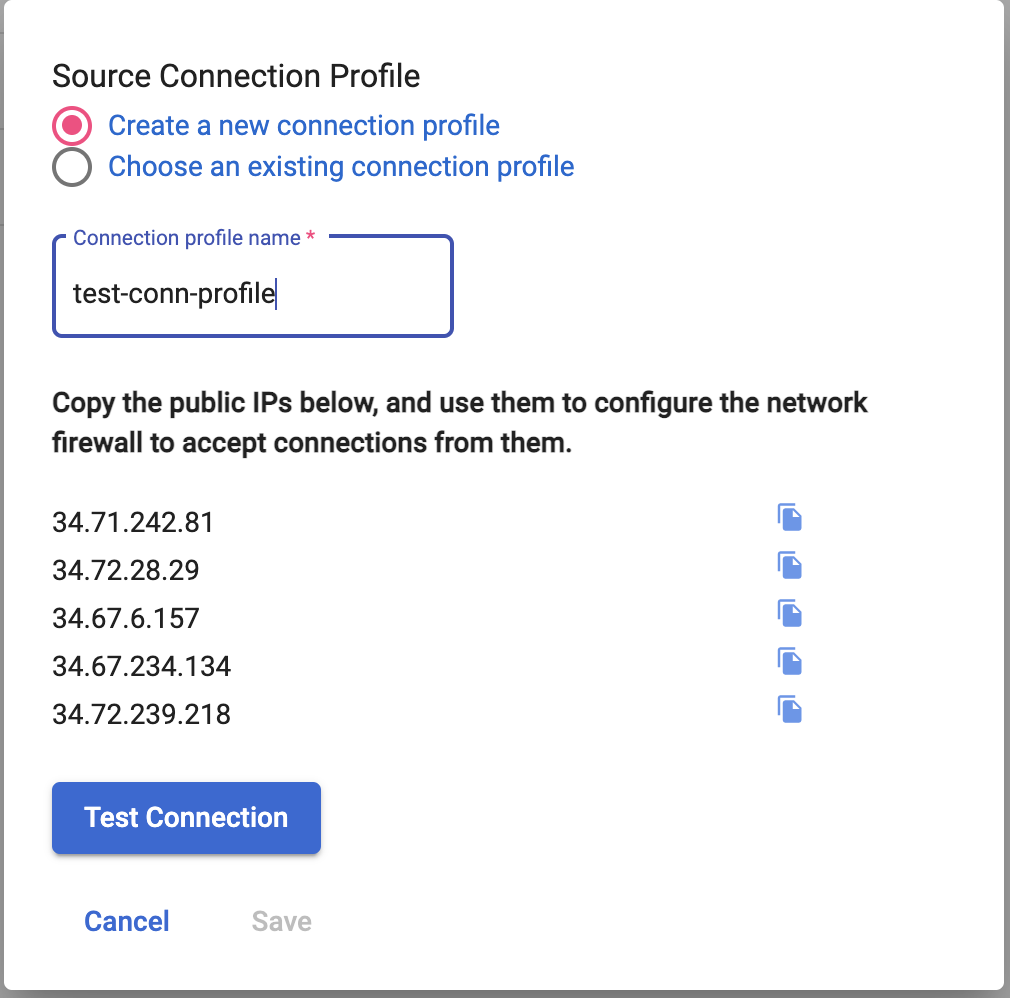
Source connection profile is used by datastream to connect to the source database and read the data from the source database. Users can either use an existing source connection profile or create a new connection profile from Spanner Migration Tool by specifying a new name for the connection profile and allowlisting the IPs.
Target connection profile
Target connection profile is used to connect to the GCS bucket where the datastream writes data written to. Users can either use an existing target connection profile or create a new one from Spanner Migration Tool by specifying a new name for the connection profile. Please ensure that the GCS bucket is empty in case you choose an existing connection profile to ensure consistency between source and spanner database. In case the user opts for a new target connection profile, Spanner Migration Tool creates a new GCS bucket with bucket name as the Migration Request ID.


Sharded Migrations Configuration
In case of sharded migrations, Spanner migration tool requires connection details of each shard to create a source connection profile and launch a Datastream for it. Alternatively, the user can also provide pre-created source connection profiles for SMT to use.
For an overview of how sharded migrations work, refer to this section
- On the prepare migration page, click on
Configure Datastreamto get started with creating/configuring connection profiles for each shard.
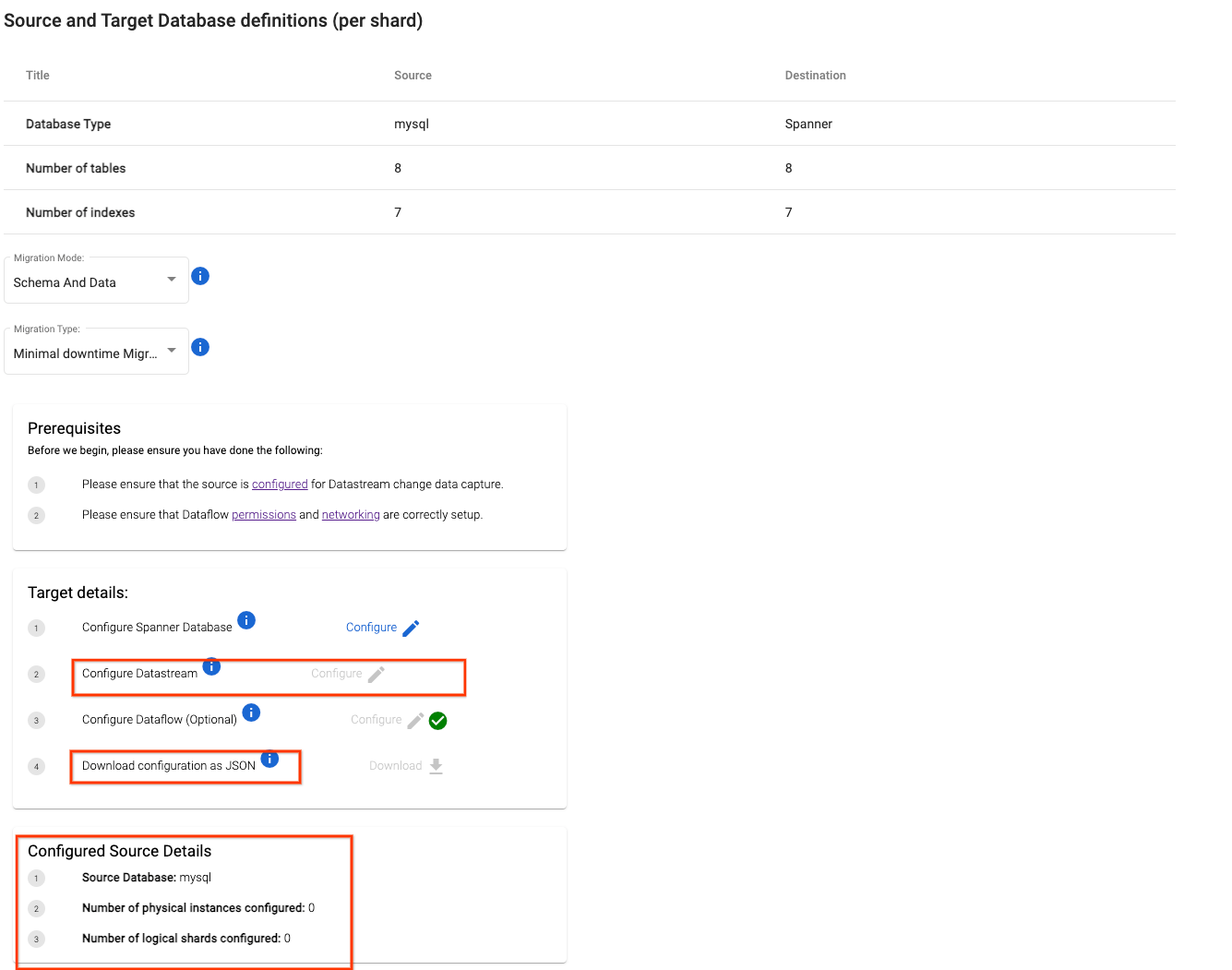
Form based configuration
Data shardId is a SMT generated identifier to track migration jobs created for a physical shard. It typically does not require a user to modify it.
-
Spanner migration tool provides multiple ways of configuring a sharded migration - via JSON or form. Configure the source and target as defined above, the same concepts apply here as well.
-
Add the database to shardId configuration mapping. Note that the value of the
shardIdprovided here will to be used to populate themigration_shard_idcolumn added to each table for the sharded migration. This field will be used to identify the source shard of MySQL while writing the data to Spanner, and has many other applications, such as reverse replication.

-
Click on
ADD MORE SHARDSto save the current shard information and configure the next. The shard counter at the top shows the total number of physical instances and logical shards configured. Refer here for details on this terminology. -
Once all shards are configured, click on
FINISH.
JSON based configuration
For JSON based configuration, creation of new resources is not supported. The connection profiles configured via JSON should already exist in Datastream.
- Select the
Textinput in the Datastream details form. - Paste the JSON configuration of the shards.
- Click on
Finish. - SMT will validate the configuration, and if valid, save it.
SMT provides an example of how a JSON based configuration looks like here.
Source and Target connection profiles can be automatically generated. Refer to this documentation to know more.
