Cloud Spanner Reverse Replication User Guide
Table of contents
- Cloud Spanner Reverse Replication User Guide
Overview
Background
Migrating a database is a complex affair, involving changes to the schema, converting the application, tuning for performance, ensuring minimal downtime and completeness during data migration. It is possible that after migration and cutover, issues/inconsistent performance are encountered on the target (Cloud Spanner) requiring a fallback to the original source database with minimal disruption to the service. Reverse replication enables this fallback by replicating data written on Cloud Spanner back to the source database.This allows the application to point to the source and continue serving requests correctly.
Reverse replication could also be used to replicate the Cloud Spanner writes to a different database, other than the source database, for performing reconciliation, validations and reporting.
How it works
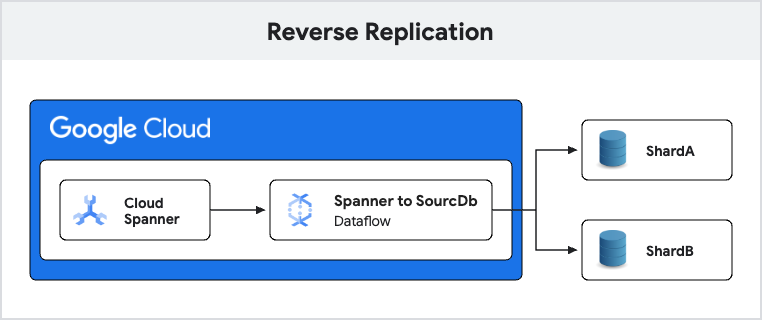
Reverse replication flow involves below steps:
- Reading the changes that happened on Cloud Spanner using Cloud Spanner change streams
- Filtering forward migrated changes ( if configured to filter )
- Transforming Cloud Spanner data to source database schema
- Verifying whether the source database already contains more recent data for the specified primary key.
- Writing to source database
These steps are achieved by the Spanner to SourceDb dataflow template.
Consistency guarantees
The pipeline guarantees consistency at a primary key level. The pipeline creates shadow tables in Cloud Spanner, which contain the Spanner commit timestamp of the latest record that was successfully written on the shard for that table. The writes are guaranteed to be consistent up-to this commit timestamp for the given primary key.
However, there is no order maintained across tables or even across various primary keys in the same table. This helps achieve faster replication.
The reverse replication is eventually consistent. Meaning once there are no retryable or severe errors and all records from Spanner have been successfully replicated, the source database reaches consistent state.
Run modes
The Dataflow job that handles reverse replication runs in two modes:
-
regular: This is the default mode, where the events streamed by Spanner change streams are picked up and converted to source compatible data types and applied to source database. It also does automatic retry of retryable errors and once the retry is exhausted, moves them to the ‘severe’ folder of the dead letter queue (DLQ) directory in GCS. Permanent errors are also moved to the ‘severe’ folder of dead letter queue.
-
retryDLQ: This mode looks at the ‘severe’ folder of DLQ and retries the events. This mode is ideal to run when all the permanent and/or retryable errors are fixed - for example any bug fix/ dependent data migration is complete.This mode only reads from DLQ and not from Spanner change streams.If the records processed from ‘severe’ directory go into retry directory - they are retried again.
Current error scenarios
The following error scenarios are possible currently:
- If there is a foreign key constraint on a table - and due to unordered processing by Dataflow - the child table record comes before the parent table record and it fails with foreign key constraint violation in case of insertion or parent record get processed before the child record in case of deletion.
- Intermittent connection error when communicating with the source database.
- There could also be some intermittent errors from Spanner like deadline exceeded due a temporary resource unavailability .
- Other SpannerExceptions - which are marked for retry
- In addition, there is a possibility of severe errors that would require manual intervention.Example a manual schema change.
Points 1 to 4 above are retryable errors - the Dataflow job automatically retries default of 500 times. In most cases, should be good enough for the retryable records to succeed, however, even if after exhausting all the retries, these are not successful - then these records are marked as ‘severe’ error category. Such ‘severe’ errors can be retried later with a ‘retryDLQ’ mode of the Dataflow job.
Before you begin
A few prerequisites must be considered before starting with reverse replication.
- Ensure network connectivity between the source database and your GCP project, where your Dataflow jobs will run.
- Allowlist Dataflow worker IPs on the MySQL instance so that they can access the MySQL IPs.
- Check that the MySQL credentials are correctly specified in the source shards file.
- Check that the MySQL server is up.
- The MySQL user configured in the source shards file should have INSERT, UPDATE and DELETE privileges on the database.
- Ensure that Dataflow permissions are present.Basic permissions and Flex template permissions.
- Ensure that the port 12345 is open for communication among the Dataflow worker VMs.Please refer the Dataflow firewall documentation for more.
- Ensure the compute engine service account has the following permission:
- roles/spanner.databaseUser
- roles/secretManager.secretAccessor
- roles/secretmanager.viewer
- Ensure the authenticated user launching reverse replication has the following permissions: (this is the user account authenticated for the Spanner Migration Tool and not the service account)
- roles/spanner.databaseUser
- roles/dataflow.developer
- Ensure that gcloud authentication is done,refer here.
- Ensure that the target Spanner instance is ready.
- Ensure that that session file is uploaded to GCS (this requires a schema conversion to be done).
- Source shards file already uploaded to GCS.
- Resources needed for reverse replication incur cost. Make sure to read cost.
- Reverse replication uses shard identifier column per table to route the Spanner records to a given source shard.The column identified as the sharding column needs to be selected via Spanner Migration Tool when performing migration.The value of this column should be the logicalShardId value specified in the source shard file.In the event that the shard identifier column is not an existing column,the application code needs to be changed to populate this shard identifier column when writing to Spanner. Or use a custom shard identifier plugin to supply the shard identifier.
- The reverse replication pipeline uses GCS for dead letter queue handling. Ensure that the DLQ directory exists in GCS.
- Create PubSub notification on the ‘retry’ folder of the DLQ directory. For this, create a PubSub topic, create a PubSub subscription for that topic. Configure GCS notification. The resulting subscription should be supplied as the dlqGcsPubSubSubscription Dataflow input parameter.
For example:
If the GCS DLQ bucket is : gs://rr-dlq
PubSub Topic is : projects/<my-project>/topics/rr-dlq-topic
Pubsub Subscription is : projects/<my-porject>/subscriptions/rr-dlq-subs
Then configure the notification like:
gcloud storage buckets notifications create --event-types=OBJECT_FINALIZE
--object-prefix=retry/ gs://rr-dlq --topic=projects/<my-project>/topics/rr-dlq-topic
- Create change stream, the below example tracks all tables. When creating a change stream, use the NEW_ROW option, sample command below :
CREATE CHANGE STREAM allstream
FOR ALL OPTIONS (
retention_period = '7d',
value_capture_type = 'NEW_ROW'
);
-
The Dataflow template creates a pool of database connections per Dataflow worker. The maxShardConnections template parameter, defaulting to 10,000 represents the maximum connections allowed for a given database. The maxWorkers Dataflow configuration should not exceed the maxShardConnections value, else the template launch will fail as we do not want to overload the database.
-
Please refer dataflow documentation on network options.
When disabling the public IP for Dataflow, the option below should be added to the command line:
--disable-public-ips
When providing subnetwork, give the option like so:
--subnetwork=https://www.googleapis.com/compute/v1/projects/<project name>/regions/<region name>/subnetworks/<subnetwork name>
Sample source shards File
This file contains meta data regarding the source MYSQL shards, which is used to connect to them. This should be present even if there is a single source database shard. The database user password should be kept in Secret Manager and it’s URI needs to be specified in the file. The file should be a list of JSONs as:
[
{
"logicalShardId": "shard1",
"host": "10.11.12.13",
"user": "root",
"secretManagerUri":"projects/123/secrets/rev-cmek-cred-shard1/versions/latest",
"port": "3306",
"dbName": "db1"
},
{
"logicalShardId": "shard2",
"host": "10.11.12.14",
"user": "root",
"secretManagerUri":"projects/123/secrets/rev-cmek-cred-shard2/versions/latest",
"port": "3306",
"dbName": "db2"
}
]
Launching reverse replication
Currently, the reverse replication flow is launched manually. Please refer the Dataflow template readme.
Observe, tune and troubleshoot
Tracking progress
There are various progress points in the pipeline. Below sections detail how to track progress at each of them.
Verify that change stream has data
Unless there is change stream data to stream from Spanner, nothing will be reverse replicated. The first step is to verify that change stream has data. Refer here on how to check this.
Metrics for Dataflow job
The progress of the Dataflow jobs can be tracked via the Dataflow UI. Refer the Dataflow guide for troubleshooting and tracking progress.
In addition, there are following application metrics exposed by the job:
| Metric Name | Description |
|---|---|
| custom_shard_id_impl_latency_ms | Time taken for the execution of custom shard identifier logic. |
| data_record_count | The number of change stream records read. |
| element_requeued_for_retry_count | Relevant for retryDLQ run mode, when the record gets enqueded back to severe folder for retry. |
| elementsReconsumedFromDeadLetterQueue | The number of records read from the retry folder of DLQ directory. |
| records_written_to_source_<logical shard name> | Number of records successfully written for the shard. |
| replication_lag_in_seconds_<logical shard name> | Replication lag min,max and count value for the shard. |
| retryable_record_count | The number of records that are up for retry. |
| severe_error_count | The number of permanent errors. |
| skipped_record_count | The count of records that were skipped from reverse replication. |
| success_record_count | The number of successfully processed records. This also accounts for the records that were not written to source if the source already had updated data. |
These can be used to track the pipeline progress. However, there is a limit of 100 on the total number of metrics per project. So if this limit is exhausted, the Dataflow job will give a message like so:

In such cases, the metrics can be viewed on the Cloud Monitoring console by writing a query:
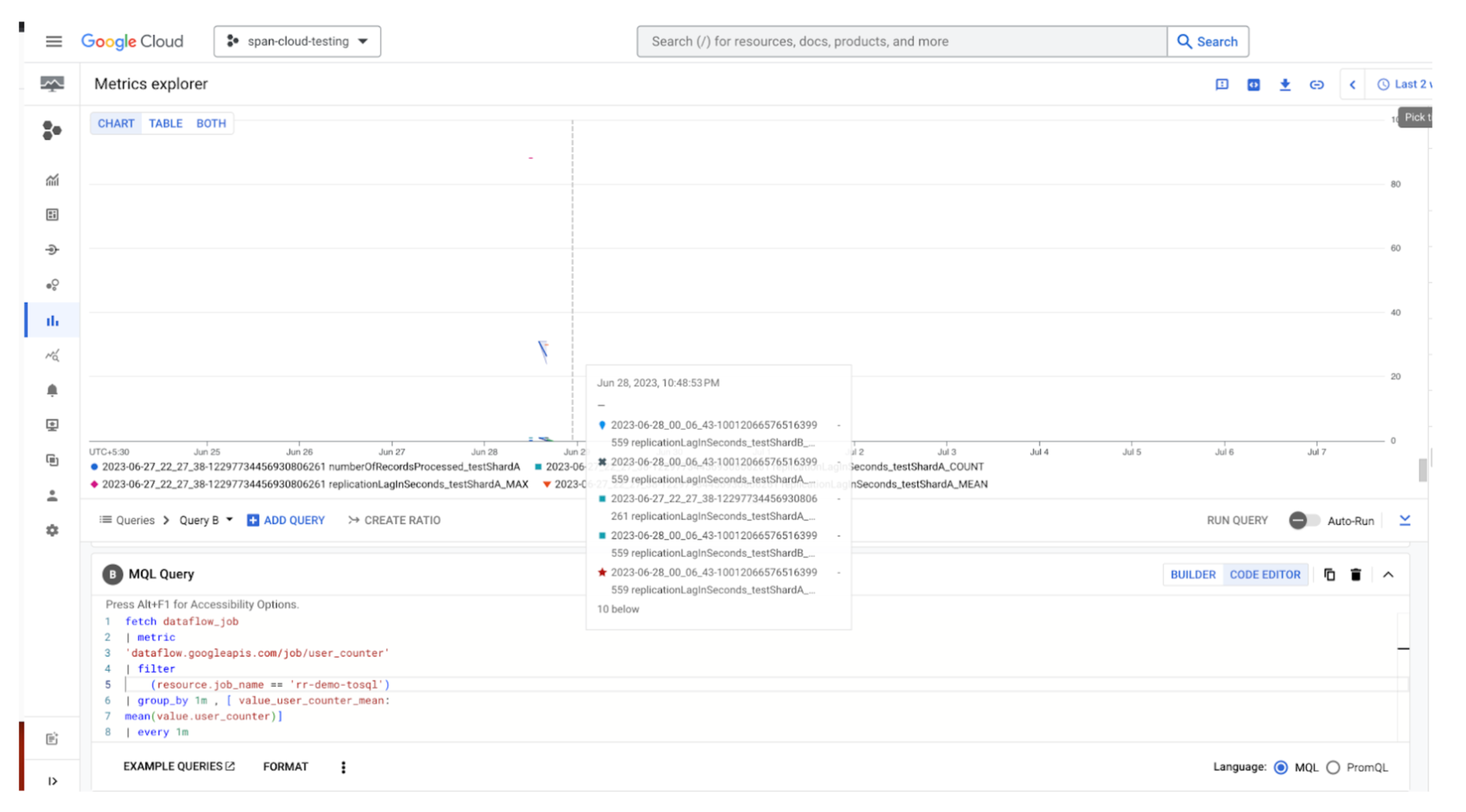
Sample query
fetch dataflow_job
| metric
'dataflow.googleapis.com/job/user_counter'
| filter
(resource.job_name == 'rr-demo-tosql')
| group_by 1m , [ value_user_counter_mean:
mean(value.user_counter)]
| every 1m
Metrics visible on Dataflow UI can also be queried via REST,official document here.
Note : Dataflow metrics are approximate. In the event that there is Dataflow worker restart, the same set of events might be reprocessed and the counters may reflect excess/lower values. In such scenarios, it is possible that counters like records_written_to_source might have values greater than the number of records written to source.Similarly, it is possible that the retryable_record_count is negative since the same retry record got successfully processed by different workers.
Verifying the data in the source database
To confirm that the records have indeed been written to the source database, best approach is to check the record count on the source database, if that matches the expected value. Note that verifying data takes more than just record count matching. The suggested tool for the same is here.
Troubleshooting
Following are some scenarios and how to handle them.
Dataflow job does not start
- Check that permission as listed in prerequisites section are present.
- Check the DataFlow logs, since they are an excellent way to understand if something is not working as expected. If you observe that the pipeline is not making expected progress, check the Dataflow logs for any errors.For Dataflow related errors, please refer here for troubleshooting. Note that sometimes logs are not visible in Dataflow, in such cases, follow these suggestions.
Records are not getting reverse replicated
In this case, check if you observe the following:
Records of below nature are dropped from reverse replication. Check the Dataflow logs to see if they are dropped:
- Records which are forward migrated.
- Shard Id based routing could not be performed since the shard id value could not be determined.
- The record was deleted on Cloud Spanner and the deleted record was removed from Cloud Spanner due to lapse of retention period by the time the record was to be reverse replicated.
- Check for issues in the dataflow job. This can include scaling issues, CPU utilization being more than 70% consistently. This can be checked via CPU utilization section on the Dataflow job UI.Check for any errors in the jobor worker logs which could indicate restarts. Sometimes a worker might restart causing a delay in record processing. The CPU utilization would show multiple workers during the restart period. The number of workers could also be viewed via here.
- When working with session file based shard identification logic, if the table of the change record does not exist in the session file, such records are written to skip directory and not reverse replicated.
Check the Dataflow logs to see if records are being dropped. This can happen for records for which primary key cannot be determined on the source database. This can happen when:
- The source database table does not have a primary key
- The primary key value was not present in the change stream data
There is higher load than the expected QPS on spanner instance post cutover
-
Change steams query incurs load on spanner instance, consider scaling up if it becomes a bottleneck.
-
If the forward migration is still running post cutover, the incoming writes on Spanner that are reverse-replicated to the source get forward migrated again. This can cause the load on Spanner to be almost double the expected QPS, as each write will get reflected twice. Also, it could lead to transient inconsistencies in data under certain cases. To avoid this, stop/delete the forward migration pipeline post cutover. If the forward pipeline is required, add custom filtration rules and build a custom forward migration dataflow template.
Ignorable errors
Dataflow retries most of the errors. Following errors if shown up in the Dataflow UI can be ignored.
- File not found exception like below. These are thrown at the time Dataflow workers auto-scale and the work gets reassigned among the workers.
java.io.FileNotFoundException: Rewrite from <GCS bucket name>/.temp-beam/<file name> to <GCS file path> has failed
-
Spanner DEADLINE_EXCEEDED exception.
-
GC thrashing exception like below
Shutting down JVM after 8 consecutive periods of measured GC thrashing.
- Large amount of logging can result in below. This does not halt the Dataflow job from processing.
Throttling logger worker. It used up its 30s quota for logs in only 17.465s
- Ephemeral network glitches results in below ignorable error.
StatusRuntimeException: UNAVAILABLE: ping timeout
Retry of Reverse Replication DLQ
When running to reprocess the ‘severe’ DLQ directory, run the Dataflow job with ‘retryDLQ’ run mode. This will reprocess the ‘severe’ directory records and apply them to source database.
Reverse Replication Limitations
The following sections list the known limitations that exist currently with the Reverse Replication flows:
- Currently only MySQL source database is supported.
- If forward migration and reverse replication are running in parallel, there is no mechanism to prevent the forward migration of data that was written to source via the reverse replication flow. The impact of this is unnecessary processing of redundant data. The best practice is to start reverse replication post cutover when forward migration has ended.
- Schema changes are not supported.
- Session file modifications to add backticks in table or column names is not supported.
- Certain transformations are not supported, below section lists those:
Reverse transformations
Reverse transformation can not be supported for following scenarios out of the box:
- The table in original database has single column while in Spanner it’s split into multiple - example POINT to X,Y coordinates
- Adding column in Spanner that does not exist in source - in this case the column cannot be replicated
- Deleting column in Spanner that is mandatory in source
- Spanner PK is UUID while source PK is auto-increment key
- Spanner table has more columns as part of PK than the source - in this case the source records having the same values as the partial primary keys are updated
- Spanner columns have greater length of string columns than source
- Spanner columns have different data type than source
- CLOB will not be read from GCS and put in source
- DELETES on Spanner that have Primary key columns different from the Source database column - such records will be dropped
- Primary key of the source table cannot be determined - such records will be dropped
In the above cases, custom code will need to be written to perform reverse transformation.Refer the customization section for the source code to extended and write these custom transforms.
When to perform cut-back
In the event that cut-back is needed to start serving from the original database instead for Spanner, following should be taken care:
- Ensure that there is a validation solution to place to validate the Spanner and source database records.
- There should bo no severe errors.
- There should be no retryable errors.
- The success_record_count which reflects the total successful records should match the data_record_count metric which reflects the count of data records read by SpannerIO. If these match - it is an indication that all records have been successfully reverse replicated. Note that for these metrics to be reliable - there should be no Dataflow worker restarts. If there are worker restarts, there is a possibility that the same record was re-processed by a certain stage. To check if there are worker restarts - in the Dataflow UI, navigate to the Job metrics -> CPU utilization.
What to do when there are worker restarts or the metrics do not match
-
Count the number of rows in Spanner and source databae - this may take long, but is it the only definitive way. If the reverse replication is still going on - the counts would not match due to replication lag - and an acceptable RPO should be considered to cut-back.
-
If the count of records is not possible - check the DataWatermark of the Write to SourceDb stage. This gives a rough estimate of the lag between Spanner and Source. Consider taking some buffer - say 5 minutes and add this to the lag. If this lag is acceptable - perform the cutback else wait for the pipeline to catchup. In addition to the DataWatermark, also check the DataFreshness and the mean replication lag for the shards, and once it is under acceptable RPO, cut-back can be done. Querying these metrics is listed in the metrics section. Also, alerts can be set up when the replciation lag, DataFreshness or DataWatermarks cross a threshold to take debugging actions.
What to do in case of pause and resume scenarios
While it should be rare to pause a running template and start it again, in case a need arises, follow these instructions:
- Always give a startTimestamp when launching the template in regular mode. Use the same startTimestamp when re-running the template. This will ensure no change stream records are lost and de-duplication is handled by checking the shadow tables.
- In case of re-run, use the same metadata database so the shadow tables are present with data of committed timestamps.
- The change streams only have 7 days of maximum retention, ensure that the rerun does not cross this retention period. Meaning, the startTimestamp should not be less that the retention period.
- Due to a current Beam bug, ensure that the change stream metadata table is deleted from the metadata database before re-run. This table will be of naming format
Metadata_<metadata database name>_<uuid> - The template does not Drain due to change stream constant polling, hence it will need to be forcefully cancelled. However, upon re-run, since the startTimestamp is the same, it would re-read the change streams and there will not be data-loss.
What to do when job has been running for duration longer than change stream retention
If the job has been running for longer than the change stream retention period, then:
- Set the startTimestamp to current date - change stream retention period.
- To avoid data-loss, ensure that the DataFreshness for the Write to SourceDb stage has not crossed the change stream retention period, meaning it should not cross 7 days - this would be an unlikey event and if alerts are set-up, it should be caught early on.
- If there are any records on the retry directory, do the below:
- Before pausing the job,remove the GCS notification
- Stop the job
- Recursively copy the retry files to a different bucket
- Delete and re-create the retry directory in GCS
- Create the notification again on the retry directory
- Recursively copy the files back to the retry directory - from the bucket it was copied to in earlier step. This step will create PubSub notifications for the retry files which the re-run job will process. This ensures that any retry records, even with commit timestamp less than the change stream retntion - will be preserved for re-run.
Best practices
-
Set the change stream retention period to maximum value of 7 days to avoid any data loss.
-
The metrics give good indication of the progress of the pipeline, it is good to setup dashboards to monitor the progress.
-
Use a different database for the metadata tables than the Spanner database to avoid load.
-
Reverse replication should start once the forward migration has ended and not in parallel to forward migration. This is to avoid reverse replicated writes to source flowing back to forward migration jobs.
Customize
The Dataflow jobs can be customized. Some use cases could be:
- To customize the logic to filter records from reverse replication.
- To handle some custom reverse transformation scenarios.
- To customize shard level routing.
To customize, checkout the open source template, add the custom logic, build and launch the open source template.
Refer to Spanner to SourceDb template on how to build and customize this.
Shard routing customization
In order to make it easier for users to customize the shard routing logic, the template accepts a GCS path that points to a custom jar and another input parameter that accepts the custom class name, which are used to invoke custom logic to perform shard identification.
Steps to perfrom customization:
- Write custom shard id fetcher logic CustomShardIdFetcher.java. Details of the ShardIdRequest class can be found here.
- Build the JAR and upload the jar to GCS
- Invoke the reverse replication flow by passing the custom jar path and custom class path.
- If any custom parameters are needed in the custom shard identification logic, they can be passed via the shardingCustomParameters input to the runner. These parameters will be passed to the init method of the custom class. The init method is invoked once per worker setup.
Sample sourceShards File
This file contains meta data regarding the source MYSQL shards, which is used to connect to them. This should be present even if there is a single source database shard. The database user password should be kept in Secret Manager and it’s URI needs to be specified in the file. The file should be a list of JSONs as:
[
{
"logicalShardId": "shard1",
"host": "10.11.12.13",
"user": "root",
"secretManagerUri":"projects/123/secrets/rev-cmek-cred-shard1/versions/latest",
"port": "3306",
"dbName": "db1"
},
{
"logicalShardId": "shard2",
"host": "10.11.12.14",
"user": "root",
"secretManagerUri":"projects/123/secrets/rev-cmek-cred-shard2/versions/latest",
"port": "3306",
"dbName": "db2"
}
]
Cost
- Cloud Spanner change stream incur additional storage requirement, refer here.
- For Dataflow pricing, refer here
- For GCS pricing, refer here.
- For PubSub pricing, refer here.
Contact us
Have a question? We are here.